The Enterprise Guide to JavaScript Rendering Audits: Uncovering SEO and AI Crawling Blindspots
A step-by-step framework to compare raw server HTML against rendered DOM, quantify JavaScript dependency, and prioritize fixes where search visibility is actually at risk.

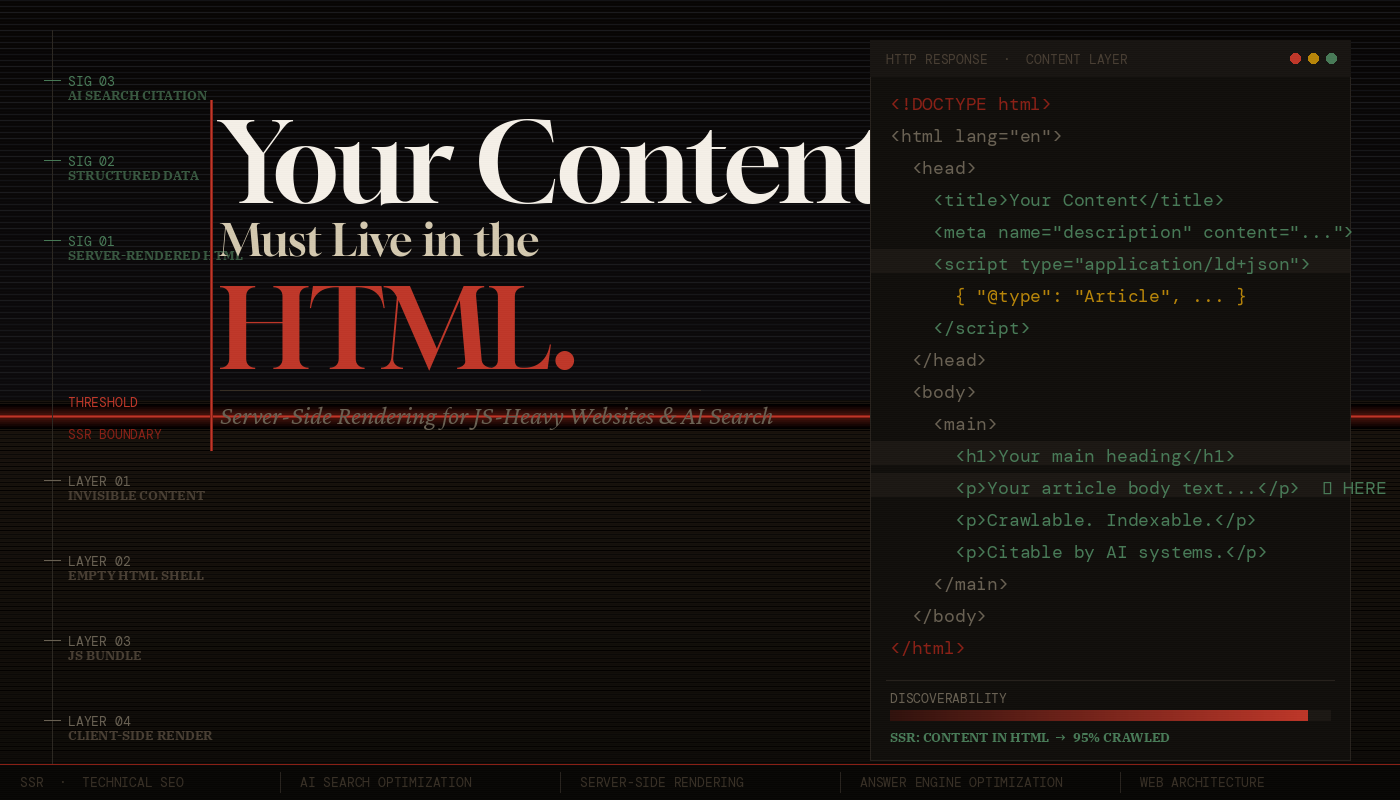
In the contemporary web landscape, JavaScript (JS) is the foundation of rich, interactive user experiences. Modern frameworks like React, Next.js, Angular, and Nuxt.js allow developers to craft beautiful, dynamic frontend applications. However, this architectural shift has introduced a massive, often undetected point of failure for search engine visibility: the rendering gap.
While Google has made monumental strides in rendering JavaScript, its processing is not instantaneous. Crucially, the web has evolved. We are no longer optimizing solely for Googlebot. The search landscape now includes a wave of LLM-based search agents, AI crawl bots, and alternative search engines—such as OpenAI’s SearchBot, AppleBot, and Perplexity—that frequently bypass the computationally expensive browser rendering cycle entirely. To save budget and infrastructure costs, these crawlers read only the raw, server-returned HTML.
If your core copy, schema markup, or internal links depend on client-side JS to render, your site is effectively invisible to a rapidly growing segment of the search market.
This guide provides a comprehensive framework to execute a Headless SEO (HS) Rendering Audit. We will explore the mathematical metrics of JS reliance, outline a step-by-step dual-crawl auditing process, and provide a roadmap to translate findings into actionable developer tasks.
1. What is an HS Rendering Audit?
A Headless SEO (HS) Rendering Audit is a highly specialized technical analysis that compares a website’s raw HTML (the code served directly from the server before any client-side scripts run) with its rendered HTML (the final Document Object Model, or DOM, after client-side JavaScript has fully executed in a headless browser).
[Raw Server HTML] --------> [Client-Side JS Execution] --------> [Rendered DOM]
(What AI bots & (The "Rendering Gap" delay) (What users &
simple crawlers see) Googlebot see)By cross-referencing these two states across a site’s templates, technical SEOs can identify:
- The Indexation Risk: High-value text, specifications, or FAQs that are completely missing from the raw source code.
- The Crawlability Gap: Critical internal anchor links (
<a href="...">) that bots cannot discover in the raw HTML, starving deep pages of authority and crawling activity. - Asset Parity Issues: Differences in page titles, meta descriptions, canonicals, or structured data between states.
2. The Core Mathematical Metrics of JS Reliance
To transform a qualitative audit into quantitative data that leadership and development teams can act upon, we must calculate exact metrics for JavaScript dependency.
A. The JavaScript Dependency Ratio (JSdep)
The JS Dependency Ratio represents the exact portion of a page’s content that relies on JavaScript to exist.
Where Wrendered is the word count of the fully rendered DOM and Wraw is the word count of the raw HTML source code.
needed for text
for competitive terms
(e.g. #root only)
- A ratio of 0.0 (0%) means perfect server-side rendering; the page requires no client-side script execution to present its text.
- A ratio of 1.0 (100%) indicates a blank client-side shell (e.g.
<div id="root"></div>) with zero indexable text in the raw source. - Any ratio above 0.30 (30%) is considered a high-risk dependency for templates targeting highly competitive search terms.
B. Word Count Difference (ΔW)
The absolute delta between the rendered and raw word counts:
- Positive Delta (+ΔW): JavaScript is dynamically adding content (e.g. loading product grids, reviews, or specifications post-load).
- Negative Delta (−ΔW): JavaScript is removing content from the page. This is a critical indicator of hydration failures, code conflicts, or content truncation scripts.
C. Link Difference (ΔL)
The delta measuring missing internal crawl paths:
Where L represents the number of discoverable internal <a href> links. If ΔL > 0, simple crawlers cannot traverse those paths, leading to isolated or orphaned pages.
D. Priority Score (P)
Because enterprise sites contain thousands or millions of pages, developer resources must be focused where they will yield the highest ROI. Calculate a Priority Score to weigh the JS dependency against actual search visibility:
By sorting your spreadsheet by this priority score, high-performing legacy pages with high JS risk will immediately bubble up to the top of the engineering queue, while low-traffic sandbox pages will be pushed to the bottom.
3. Step-by-Step: Carrying Out the HS Render Audit
Executing this audit requires a crawl engine capable of capturing both rendering states. Standard tools like Screaming Frog SEO Spider, Lumar, or enterprise-level crawlers are perfectly suited for this task.
[Start Crawl Process]
│
┌────────┴────────┐
▼ ▼
[Crawl Phase 1] [Crawl Phase 2]
(Raw HTML) (JS Render Mode)
│ │
└────────┬────────┘
▼
[Align Datasets via URL]
│
▼ Calculate Metrics:
- JS Dependency Ratio
- Word Count & Link Deltas
- Priority Score (via GSC Data)
│
▼
[Prioritized Audit Deck]Step 1: Template-Based Sampling
While crawling millions of URLs with JavaScript enabled is incredibly resource-intensive, rendering architectures are templated. Segment your audit by sampling 50 to 100 URLs from each major site template:
- Homepage
- Product Listing Pages (PLPs) / Category Hubs
- Product Detail Pages (PDPs)
- Dynamic Tools (Wizards, Configurator Tools, Calculators)
- Informational Content (FAQs, Blog/Editorial posts, Help Centers)
Step 2: Configure the Dual-Crawl Engines
Run two parallel crawls of your URL sample, or configure a single crawl that exports both states:
- The Raw HTML Crawl: Set your user-agent to a standard bot (like Googlebot) but disable JavaScript execution. This downloads the raw text response directly from your server.
- The JS Render Crawl: Enable JavaScript execution using a headless browser (Chromium). Set an AJAX timeout (typically 3–5 seconds) to ensure asynchronous API queries and DOM manipulation scripts complete their cycles.
Step 3: Align and Calculate the Delta Spreadsheet
Export your data and merge the crawls into a single worksheet. Your master spreadsheet should contain:
- URL
- Raw Word Count vs. Rendered Word Count
- Raw Link Count vs. Rendered Link Count
- GSC Impressions (Last 30 Days)
- Calculated metrics: JSdep, ΔW, ΔL, and Priority Score (P)
4. Mapping JS Dependencies by Template
When analyzing your final audit sheet, you will notice that rendering gaps cluster around specific page templates. Here is how to diagnose and resolve the most common dependencies across four core enterprise templates:
A. Product Listing Pages (PLPs) / Category Hubs
The Scenario: In modern headless e-commerce setups, product category pages are often built as visual grids. These grids are populated dynamically via client-side API fetches that execute after the page container loads.
The Audit Finding: Category hubs frequently show a JS Dependency Ratio of 35% to 65%. While the header, footer, and category intro copy exist in the raw HTML, the actual product cards (including names, pricing, and links to individual PDPs) only appear after JS runs.
The SEO Impact: Search engines crawling the raw HTML see an “empty storefront.” Because no product links exist in the server response (ΔL is highly positive), internal PageRank distribution collapses, and search crawlers struggle to discover or index deep product detail pages.
The Fix: Transition to Server-Side Rendering (SSR) for the initial category viewport. Ensure that at least the top 12 to 24 product cards—including their titles, prices, and valid <a href> anchor tags—are fully baked into the initial server-rendered HTML.
B. Product Detail Pages (PDPs)
The Scenario: Product pages often contain rich interactive sections, such as dynamic spec tables, real-time stock checkers, customized tab interfaces, and third-party review widgets.
The Audit Finding: PDPs typically exhibit an average JS Dependency Ratio of 15% to 30%. The delta (ΔW) reveals that 300 to 600 words per page—representing user reviews, specs, and related product items—are missing from the raw HTML.
The SEO Impact: While the main product title and primary description index perfectly, search engines cannot index long-tail keywords embedded within customer reviews or dynamic spec tables because they do not exist in the raw source code.
The Fix: Pre-render specification matrices and review widgets at the server level. If loading reviews dynamically is required for page performance, ensure the first page of reviews (e.g. the top 5 featured reviews) is pre-rendered in the initial HTML response.
C. Interactive Tools (Compare Pages & “Help Me Choose” Wizards)
The Scenario: Brands build highly engaging comparison matrices and custom recommendation wizards to guide users through complex purchasing decisions.
The Audit Finding: These landing pages consistently yield a JS Dependency Ratio of 60% to 85%. When crawled without JS, the raw HTML is an empty shell containing almost nothing but a container tag like <div id="wizard-app"></div>.
The SEO Impact: Despite being high-intent, highly linkable assets, these pages are indexed as thin or low-quality content, causing them to perform poorly in search results.
The Fix: Serve a static, SEO-friendly fallback version of the core product list and comparison table in the raw HTML. Alternatively, utilize hybrid rendering to hydrate interactive UI controls on top of a static, readable layout.
D. Customer Support & FAQ Hubs
The Scenario: Troubleshooting guides, customer service portals, and FAQs are often built using single-page applications (SPAs) or hosted on modern headless subdomains.
The Audit Finding: These templates frequently exhibit a JS Dependency Ratio of nearly 100%. When crawled without JavaScript, the indexable word count drops to zero (excluding global menus).
The SEO Impact: Users searching for highly specific troubleshooting terms (e.g. “How do I restart model X after a power failure?”) are directed to third-party forums rather than your authoritative support articles, because your self-help guides are invisible to non-rendering bots.
The Fix: Migrate informational hubs to a Static Site Generation (SSG) or Server-Side Rendering (SSR) architecture. Informative support documents do not require client-side execution to be read by humans or search engine crawlers.
Rendering gaps almost always cluster by template, not by individual URL. Fix the architecture once at the template level and you resolve hundreds or thousands of URLs in a single engineering sprint.
5. Unmasking the “Negative Word Count” Trap
A highly critical anomaly uncovered during a rendering audit is a Negative Word Count Difference (−ΔW). This occurs when the raw HTML actually contains more indexable text than the rendered HTML.
Raw HTML Word Count: [==========================] 3,000 words
Rendered DOM Word Count: [================] 1,800 words
\______________/
JS Overwrote/Removed 1,200 words!Why does this happen?
- Hydration Mismatches: When a client-side JS framework (like React or Vue) initializes over pre-rendered server HTML, it attempts to “hydrate” the elements. If the server-rendered HTML and client-side state do not match perfectly, the virtual DOM can fail to reconcile, completely overwriting or deleting entire sections of content.
- Dynamic Truncation/Accordion Scripts: Scripts designed to hide text behind “read more” buttons, collapse accordions, or paginate tabs can accidentally delete or omit those text blocks from the active DOM on page load.
- Template Redirects and Canonical Swaps: A client-side script may dynamically alter canonical tags or trigger a soft redirect, causing the renderer to load a completely different page state than what was parsed in the raw HTML.
This creates extreme volatility. When a crawler fetches the raw HTML, it indexes a specific set of keyword-rich content. However, when the crawler returns later to render the page, that content has disappeared. This constant “ping-ponging” of indexable content signals search engines that the page is unstable, degrading its keyword authority.
6. Actionable Engineering Remediation Framework
When presenting the findings of your HS Rendering Audit to engineering teams, avoid vague requests like “make the site more search-friendly.” Instead, speak their language by recommending specific, standard web rendering strategies.
| Strategy | How It Works | Best Used For | SEO Impact |
|---|---|---|---|
| Server-Side Rendering (SSR) | The server executes JavaScript on every request, generates the complete HTML, and delivers it to the browser. | Product Detail Pages (PDPs), Category Hubs (PLPs). | Excellent. 100% content visibility and fast TTFB. |
| Static Site Generation (SSG) | Pages are pre-compiled into static HTML files during the build process and distributed via CDN. | Support Pages, FAQs, Blog/Editorial Articles, Homepage. | Excellent. Unbeatable page speeds and perfect crawlability. |
| Incremental Static Regeneration (ISR) | Static pages are served immediately but regenerated in the background at set intervals. | High-volume inventory pages, generic offer hubs. | Very Good. Balances speed with dynamic data updates. |
| Dynamic Rendering (Fallback) | The server detects the user-agent. If it’s a bot, it serves a pre-rendered HTML snapshot; if a human, it serves the client-side app. | Legacy SPA setups where migrating to native SSR is cost-prohibitive. | Acceptable (Temporary). Not recommended long-term, but resolves immediate bot indexation issues. |
The “Progressive Enhancement” Rule of Thumb
When building any component, ask your development team this question. If the answer is no—if product cards disappear, specifications vanish, or internal links break—then that component is built on a high-risk JS dependency that must be refactored.
Open DevTools → Settings → Disable JavaScript, reload any high-priority URL from your audit spreadsheet, and compare what you see to your raw-crawl word counts. Discrepancies confirm your metrics in the real browser.
7. Conclusion
As search engines evolve into complex AI answer engines, the availability and crawlability of your raw, structured data has become a critical business requirement. An HS Rendering Audit is no longer a niche, advanced technical task—it is a foundational requirement for any enterprise operating on modern JavaScript web frameworks.
By identifying template-level JS dependencies, resolving link and word count deltas, and prioritizing engineering resources based on search volume at risk, you can successfully bridge the gap between elegant modern frontend design and flawless search visibility.
Export your first dual-crawl sample this week: 50 URLs per template, merge on URL, sort by Priority Score (P), and ship the top 10 URLs to engineering with explicit SSR/SSG recommendations—not generic SEO tickets.